Following on from a previous post, I wanted to explore what effect various kinds of strategies for solving Wordle have on how quickly you solve it.
So I implemented Wordle in python, and then spent a while trying to find a good word list to use as a basis. Now, I know that you can inspect the Wordle page itself and find the list of words it uses for validating real words and the list of wordle answers, but I don’t want to use that list, so I made my own. I’ve put the code up at github.
For now, let’s look at whether it makes sense to do a couple of
guesses to cover lots of common letters,
or whether you should just go “hard mode” from guess two.
(Every first guess is hard mode compatible, since you’ve not got any constraints yet).
So the simple solver I’ve implemented so far basically assigns each word a score
based on how near the top each letter is in its position.
So, for example, for the word list I’m using in this experiment (multi.txt),
the letter positions table looks as follows:
Top letters in position 1
S,B,C,T,A,P,M,F,R,L
Top letters in position 2
A,O,E,I,R,L,U,H,T,N
Top letters in position 3
A,I,R,O,E,N,L,T,U,S
Top letters in position 4
E,N,A,T,I,L,R,C,O,S
Top letters in position 5
S,E,Y,T,N,R,D,A,L,H
The word CARES scores 4 since:
Cis the third most common first place letter so it scores 2Ais the most common second place letter so it scores 0Ris the third most common third place letter so it scores 2Eis the most common fourth place letter so it scores 0Sis the most common fifth place letter so it scores 0
Once you’ve ordered words by their score, you pick the lowest scoring word
that isn’t ruled out by previous guesses.
The solver always starts with CARES, since it’s the lowest scoring word.
And you keep going until you guess the word.
This gives us our baseline.
The mean number of guesses to get the word for this solver is 3.7
with a variance of about 0.96.
Can you improve your chances by making your second guess a word that shares
no letters with your first, even if your first guess wasn’t all grey?
Obviously, this is not permitted in hard mode,
but does doing so actually make things easier?
Well, we can modify the above solver to, first guess
a set list of words in order, and then revert to the strategy outlined above.
Doing so, and guessing CARES and then POINT, before reverting to
the standard strategy has roughly the same mean number of guesses, but a smaller variance (0.61).
So you are much less likely to guess it in 2
(since unless CARES is all grey, it’s definitely not POINT)
but it means you’re more likely to get it in fewer guesses as compared to the standard approach.
What about guessing three disjoint words?
Well, for the word list I am currently experimenting with,
there’s no word with five distinct letters that doesn’t share a letter with CARES or POINT,
but we can try adding FULLY as a third guess.
Predictably, the mean goes up to 4.3 (since you’re pretty much guaranteed not to get it in 3)
but the variance comes down some more (to 0.31).
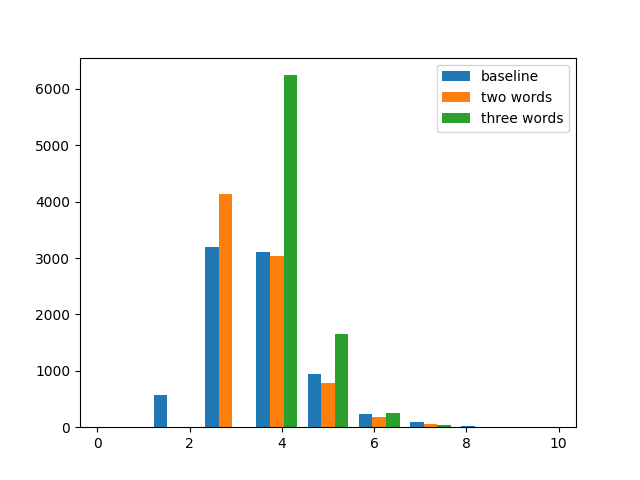
So, to some extent, it comes down to personal preference how much variance you want to
trade off against mean number of guesses.
This is, of course, for a computer with a large word list readily to hand.
I often use the two words or three words strategy because I can’t think of any that fit
with the letters I’ve identified with guess 1.
(I use COALS, BRINE, THUMP).
There’s lots of caveats one could articulate about this analysis, and there’ll probably be some more posts on this topic in the near future, exploring some of those issues.